![]()
DNADeoxyribonucleic acidThe genetic blueprint molecule |
![]()
Paul May, School of Chemistry, University of Bristol
![]()
Molecule of the Month January 2000
Also available: JSMol version
![]()

 In the autumn of 1951, James Watson (left) and Francis Crick (right) started work on unravelling the structure of DNA. It was known at the time that DNA was present in the nucleus of every living cell, and that it had something to do with heridity, but without a knowledge of its structure little more could be understood about how it actually worked. They approached the problem with the same methodology that had been pioneered by Linus Pauling, who after years of exhaustive study had earlier discovered that many proteins exhibited a helical structure. Their task was to devise a structure which would account for all the chemical and X-ray evidence, and at the same time be consistent with all the structural features of the units involved - such as the size and shape, bond angles and lengths, configurations and conformations. X-ray diffraction photographs of DNA fibres taken by Rosalind Franklin and Maurice Wilkins showed a distinctive X-shape, which was characteristic of a helix structure, but strong arcs on the meridian indicated a repeating structure 3.4 Å apart. And from the chemical evidence, it was known that part of the structure was comprised of 4 heterocyclic bases, adenine (A), guanine (G), cytosine (C) and thymine (T), somehow linked together with sugar units and phosphates. One of the biggest puzzles was that although the proportion of these bases varied from one DNA to another, it was always found that the number of A = T, and G = C.
In the autumn of 1951, James Watson (left) and Francis Crick (right) started work on unravelling the structure of DNA. It was known at the time that DNA was present in the nucleus of every living cell, and that it had something to do with heridity, but without a knowledge of its structure little more could be understood about how it actually worked. They approached the problem with the same methodology that had been pioneered by Linus Pauling, who after years of exhaustive study had earlier discovered that many proteins exhibited a helical structure. Their task was to devise a structure which would account for all the chemical and X-ray evidence, and at the same time be consistent with all the structural features of the units involved - such as the size and shape, bond angles and lengths, configurations and conformations. X-ray diffraction photographs of DNA fibres taken by Rosalind Franklin and Maurice Wilkins showed a distinctive X-shape, which was characteristic of a helix structure, but strong arcs on the meridian indicated a repeating structure 3.4 Å apart. And from the chemical evidence, it was known that part of the structure was comprised of 4 heterocyclic bases, adenine (A), guanine (G), cytosine (C) and thymine (T), somehow linked together with sugar units and phosphates. One of the biggest puzzles was that although the proportion of these bases varied from one DNA to another, it was always found that the number of A = T, and G = C.
 |
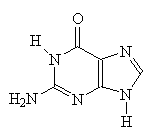 |
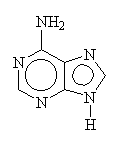
| Adenine | Guanine |
 |
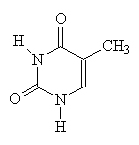 |
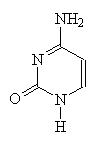
| Cytosine | Thymine |
The 4 bases which make up DNA
.
Using molecular models, Watson and Crick devised a structure in which all of the building blocks fitted together without crowding or overlapping, and which permitted a great deal of stabilisation by Hydrogen bonds. Moreover, these Hydrogen bonds were of the kind that Pauling had shown to be the strongest and therefore the most important for determining structure in proteins, namely N-H-N or N-H-O.
In April 1953 Watson and Crick published their structure - the now famous double helix. This brilliant accomplishment ranks as one of the most significant discoveries in science because it led the way to an understanding of genetics in terms of the molecules involved. In 1962 they received the Nobel prize for Medicine in recognition of this achievement, along with Maurice Wilkins of Kings College London who had performed the initial X-ray crystallography studies.
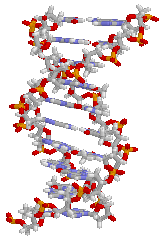 |
A very small section of DNA showing the double-helix structure linked by bases, like the rungs on a twisted ladder. |
In every living cell there are found nucleoproteins - substances made up of proteins combined with natural polymers, the nucleic acids. Where the backbone of a protein molecule is a polyamide (or polypeptide) chain, the backbone of a nucleic acid molecule is a polyester chain (called a polynucleotide chain). The ester is derived from phosphoric acid (the acid portion) and a sugar (the alcohol portion).
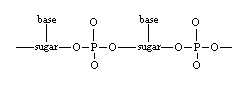
Polynucleotide chain
The sugar is D-ribose, which is in the group of nucleic acids called ribonucleic acids (RNA), and D-2-deoxyribose forms the basis of DNA. The 2-deoxy simply indicates the lack of an -OH group at the 2 position. Thus DNA stands for deoxyribonucleic acid.
Attached to the carbon at one side of the sugar is one of the 4 bases, A, C, G, or T. The base-sugar unit is called a nucleoside. Attached to the other side of the sugar is a phosphoric acid unit, linking the nucleoside to the neighbouring sugar. The base-sugar-phosphoric acid unit is called a nucleotide.
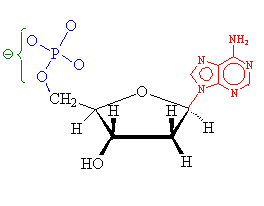
Adenosine, a nucleotide containing adenine (red), deoxyribose (black) and phosphoric acid (blue).
Two of these polynucleotide chains, which can be many millions of nucleotides long, then wrap around one another to form the double helix structure, with every A group H-bonding to the T group on the adjacent chain (see here for A-T molfile), and every G group H-bonding to its matching C group (see here for G-C molfile).
The double helix of DNA controls heredity on the molecular level. The hereditary information is stored as the sequence of bases along the polynucleotide chain - a message written in a language of only 4 letters, A, C, G and T. DNA both preserves this information, and uses it. It does this through 2 properties:
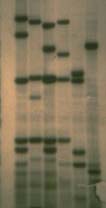 Since the DNA within any species, and to any individual within that species, is unique, it can be used as a means of identification. DNA can be extracted from organic remains (blood, saliva, etc) left at crime scenes to identify the criminal. It can also be used to determine parentage, the gender of animals and birds (where it is difficult to do so by just looking at them!), and to prove whether traditional medicines contain extracts from endangered species. This process is called DNA fingerprinting.
Since the DNA within any species, and to any individual within that species, is unique, it can be used as a means of identification. DNA can be extracted from organic remains (blood, saliva, etc) left at crime scenes to identify the criminal. It can also be used to determine parentage, the gender of animals and birds (where it is difficult to do so by just looking at them!), and to prove whether traditional medicines contain extracts from endangered species. This process is called DNA fingerprinting.
![]()
![]()
{kind=link}